Преамбула
Когда-то давно поднимал тему network namespaces (копия), механизма Linux, позволяющего на машине с одним физическим сетевым интерфейсом организовать несколько независимых сетевых стеков, т.е. виртуальных сетевых интерфейсов с разными настройками (IP-адресом, маршрутизацией, правилами IPTABLES и т.д.). Возник вопрос, как к уже настроенным сетевым неймспейсам добавить еще один.
Это не просто, а очень просто.
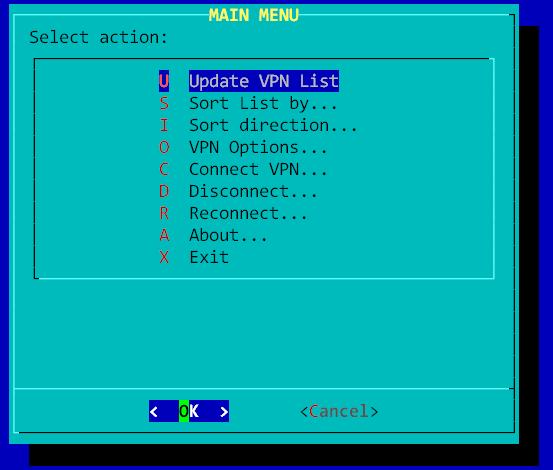
Итак, имеется система такой вот конфигурации:

А требуется нечто такое:

Добавление дополнительного network namespace’а
1. Создаем новый netspace с именем, например, linkns:
ip netns add linkns
2. Создаем два связанных между собой виртуальных сетевых интерфейса veth2 и veth3:
ip link add veth2 type veth peer name veth3
3. Поднимаем интерфейс veth2, который останется в основном неймспейсе:
ifconfig veth2 0.0.0.0 up
4. Подождали, интерфейс поднялся (для проверки вызываем ifconfig без параметров):
veth2: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
ether 3a:8d:6a:40:b8:38 txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
5. Ассоциируем veth3 с новым неймспейсом linkns:
ip link set veth3 netns linkns
6. Добавляем новый интерфейс (veth2) к интерфейсам ранее созданного моста br0
brctl addif <имя_моста> <имя_интерфейса>
brctl addif br0 veth2
Можно проверить список интерфейсов командой:
brctl show br0
Вывод команды:
bridge name bridge id STP enabled interfaces
br0 8000.3a8d6a40b838 no eth0
veth0
veth2
Теперь изначальная схема моста

Превращается в такую:

Включать/отключать физические сетевые интерфейсы или мост не нужно, все было сконфигурированно ранее. Осталось произвести настройки внутри namespace linkns:
1. Поднимаем сетевой интерфейс veth3 внутри неймспейса linkns и присваиваем ему IP.
ip netns exec linkns ifconfig veth3 192.168.0.21 netmask 255.255.255.0
2. Прописываем внутри нетспейса маршрут по умолчанию:
ip netns exec linkns ip route add default via 192.168.0.1 dev veth3 src 192.168.0.21
3. Поднимаем внутри namespace’а loopback-интерфейс:
ip netns exec linkns ifconfig lo 127.0.0.1
4. Если нужно, добавляем файлы конфигурации для namespace’а, например resolv.conf (копия)
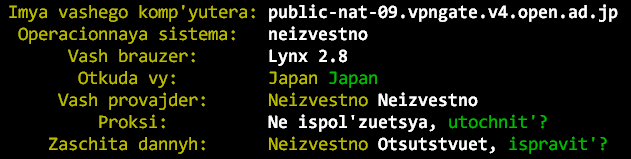
5. Проверяем работоспособность неймспейса.
Проверяем сетевые устройства:
ip netns exec linkns ifconfig
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
veth3: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.0.21 netmask 255.255.255.0 broadcast 192.168.0.255
inet6 fe80::8c12:30ff:feda:fe06 prefixlen 64 scopeid 0x20<link>
ether 8e:12:30:da:fe:06 txqueuelen 1000 (Ethernet)
RX packets 55 bytes 4391 (4.2 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 17 bytes 1458 (1.4 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ping:
ip netns exec linkns ping 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=111 time=13.3 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=111 time=11.6 ms
64 bytes from 8.8.8.8: icmp_seq=3 ttl=111 time=12.0 ms
...
и интернет:
ip netns exec linkns lynx google.com

ФАНФАРЫ!