Еще одну забавную софтину нашел. Изначальный автор вообще целую кучу подобного софта сделал на своем фреймворке, бухгалтерия, платежные поручения, еще что-то, но мы нашли только записную телефонную книжку. Потом может переложим на old-dos, если желание будет.
Экран загрузки
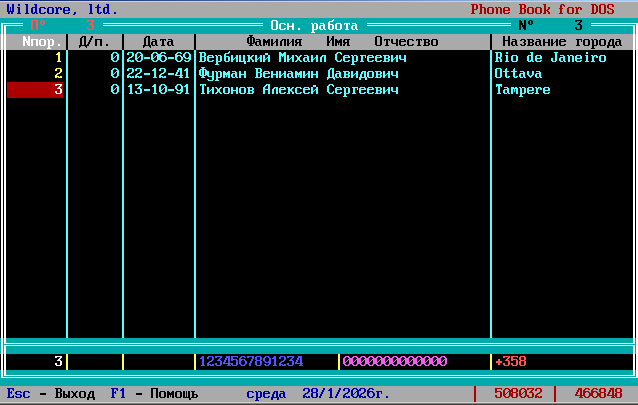
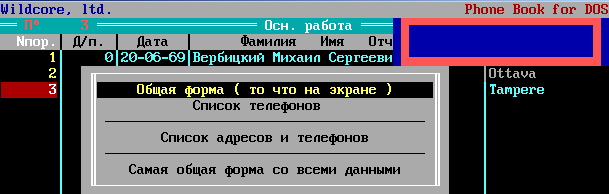
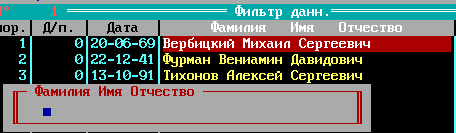
Главное окно
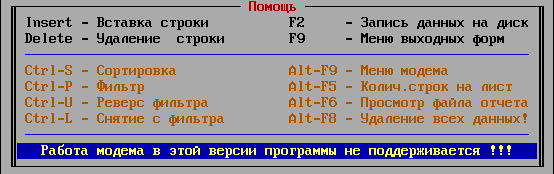
Основная помощь
Как добавить запись
1. Становимся на пустую строку и нажимаем Ins, по полям можно ходить курсором —> <—,ввод данных в соответствующее поле по нажатию кнопки ПРОБЕЛ.
2. При вводе даты надо нажимать ENTER между числом, месяцем и годом. Иначе не переключится на следующий элемент даты. Год двухзначный. Разработчик не знал, что программа доживет до 2000-го года и где-то всплывет. Скорее всего, и разработчика уже нет давно.
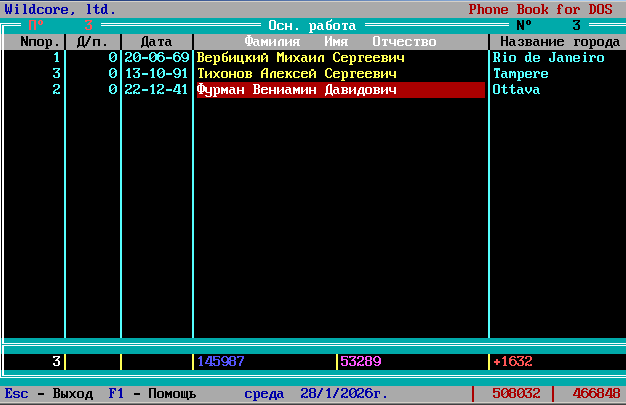
Как добавить (посмотреть) адрес и телефон
Нажать TAB на заполненной строке:
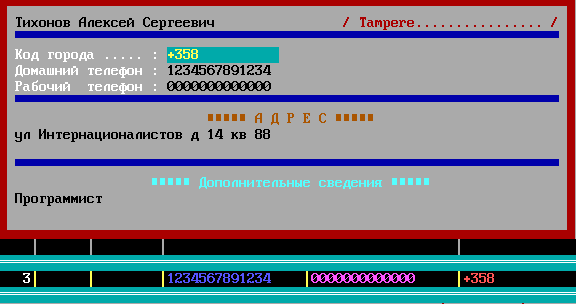
Все поля текстовые, только разной длины, переход между полями стрелками курсора, режим редактирования по нажатию ПРОБЕЛ, сохранение поля по нажатию ENTER. Выход из карточки по ESC.
Дополнительные комбинации клавиш
Видимо, наследие более общего фреймворка, в основной помощи не оговоренные.
F2 — Сохранение данных без диалога
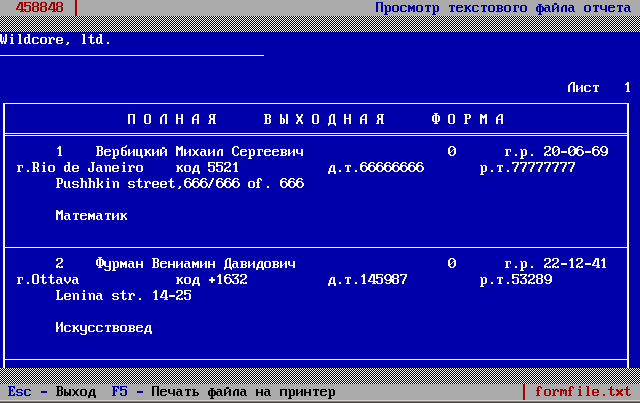
F9 — Выходная форма (вывод справочника на печать или в файл)
Ctrl+Y — Реверс сортировки
TAB, Ctrl-I — карточка с данными
Ctrl-P — Поиск по полю
Ctrl-S — Сортировка по возрастанию
Alt-X — Выход без сохранения
Выход из программы
По ESC с главного окна, перед выходом будет предложено сохранить базу данных.

Формат базы данных
База данных хранится в файле _BUF.DAT в каталоге программы, и представляет собой набор записей языка Pascal (Borland Pascal).
Описание полей базы данных:
Описание формата базы телефонной книжки:
Num:LongInt; - Номер порядковый (Глючит и не используется на практике)
Num2:LongInt; - Номер дополнительный (Неизвестно зачем нужен)
Date1:LongInt; - Дата рождения (Глючит после 2000 г.)
IO:String[35]; - ФИО
Sity:String[16]; - Город
Kod:String[13]; - Код города
Dom:String[13]; - Домашний телефон
Rab:String[13]; - Рабочий телефон
Addr1:String[67]; - Адрес
X1:word; - Зарезервировано
Addr2:String[67]; - Продолжение адреса
X2:word; - Зарезервировано
Dop1:String[67]; - Дополнительные сведения
X3:word; - Зарезервировано
Dop2:String[67]; - Продолжение дополнительных сведений
X4:word; - Зарезервировано
X5:word; - Зарезервировано
Конвертер для базы данных
Ну когда-то надо было, потому он конвертит _BUF.DAT в файл READTEL.TXT, который представляет собой CSV-файл с разделителем ‘|‘.
Исходный код конвертера
Пример выходного файла
Дополнительные параметры запуска
TELEFON2.EXE install — включение/отключение защиты от копирования и смены названия организации в главном окне (где Wildcore, ltd). Не работает, т.к. нужен прямой доступ к жесткому диску, защита и данные сохраняются непосредственно в экзешнике.
Для включения защиты надо ввести пустой пароль на запрос после команды TELEFON2.EXE install, для деактивации защиты, опять вызвать программу с параметром TELEFON2.EXE install, в качестве пароля ' Satanic 666.' с начальным пробелом и без кавычек.
TELEFON2.EXE demo — демонстрационный режим, запуск без защиты (если она установлена).
Отчеты Virustotal
Чтоб говноеды мозги не ебали:
TELEFON2.EXE
READTEL.EXE
Весь архив
Скачать
С Mega.NZ
Google.Drive




![[info]](http://tolik-punkoff.com/wp-content/plugins/lj-ljr-users/img/userinfo-ljr.gif)