Аналог линуксового clamav.
Решил потестировать, походу на нем и останусь, вроде работает и неплохо.
1. Естественно, сносим все старые антивири.
2. Качать отсюда
3. На официальном сайте ссылка в разделе download битая, хз почему, надо качать с sourceforge [2]
4. Для ГОРФ недоступно, так что пользуйтесь Tor или VPN
ClamAV исключительно сканер, так что на венде к нему надобен еще и монитор.
Монитор тоже опенсурсный, скачать можно отсюда
Настройка монитора:
После запуска антивируса, устанавливаем монитор, перезагружаемся, и выставляем галочки вот так:

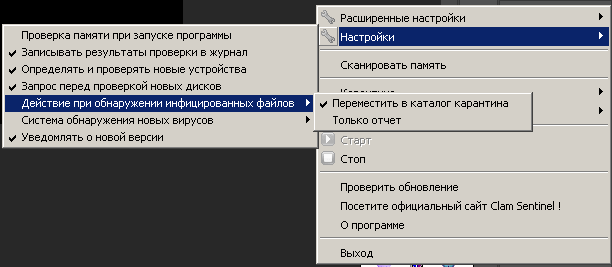
Щелкаем по значку монитора правой кнопкой мыши, далее выбираем Настройки —>Настройка обнаружения новых вирусов —> Обнаруживать только подозрительные файлы. Если выбрать Обнаруживает подозрительные файлы и предупреждает об изменениях в системе, то реально заебет всплывашками, будут на каждый чих, вплоть до сохранения документа в ворде.
Включение/выключение:
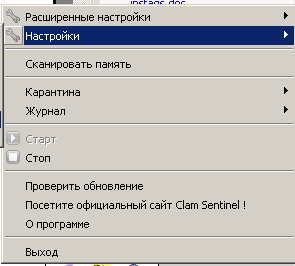
По пункту Стоп выключаем, если надо, по кнопке Старт включаем. В пункте Карантина (да русификацию делал какой-то индус), можно открыть папку с файлами, перемещенными в карантин.
В Настройки —> Действия при обнаружении инфицированных файлов ставим галочку Переместить в каталог карантина, иначе по умолчанию будет только всплывашку выдавать, если что-то обнаружит. При обнаружении почему-то всплывашки очень краткие, можно не заметить.
Значки запущенного монитора (первый слева) и антивируса:

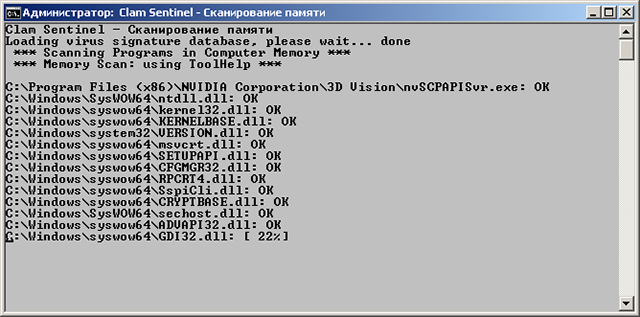
Сканирование памяти:
Можно тоже сделать в меню монитора. Немного минус, оно медленное, по сравнению с Авирой или DrWeb, но тут вопрос риторический, вам шашечки или ехать:
Хотя, при установке, что антивирус, что монитор, прекрасно садятся в автозагрузку через Реестр, и с нужными (админскими) правами, есть проблема, если их вручную выгрузить, то без рестарта системы, их придется загружать тоже вручную. Для этого надо выполнить два батника от имени администратора.
Запуск антивируса (выполняем первым):
@echo off
rem launch clamwin manual
rem run this as administrator right
echo "Starting ClamWin..."
"C:\Program Files (x86)\ClamWin\bin\ClamTray.exe" --logon
pause
Потом запускаем монитор:
@echo off
rem launch clamwin manual
rem run this as administrator right
echo "Starting monitor..."
"C:\Program Files (x86)\ClamSentinel\ClamSentinel.exe"
К сожалению, только вручную. Говорили, что обновления закрыты только для ГОРФ, и можно спокойно обновляться автоматически через Tor (с помощью питоновского скрипта), но оказывается, разработчики антивиря посадили сайт на клаудфрару противную ебаную, и она на автомате режет немецкие, вьетнамские, камбоджийские и нидерландские IP, а также любые выходы Tor-нод и VPN. Выскакивает капча, «подпердите, что вы чебурек».
Так что раз в день (или когда вылезает всплывашка, что не удалось обновиться), скачиваем ручками три файла:
main.cvd
daily.cvd
bytecode.cvd
Третий файл, кстати, обновляется не каждый день.
Антивирусные базы обычно находятся здесь:
"C:\Documents and Settings\All Users\.clamwin\db"
Для удобства наскриптил батник, чтоб копировал базы из загрузок в нужный каталог. Запускать от имени администратора:
@echo off
rem update clamwin manual
rem run this as administrator right
echo "Update Database..."
echo "Copy main.cvd..."
copy C:\Downloads\main.cvd "C:\Documents and Settings\All Users\.clamwin\db\main.cvd"
echo "Copy daily.cvd..."
copy C:\Downloads\daily.cvd "C:\Documents and Settings\All Users\.clamwin\db\daily.cvd"
echo "Copy bytecode.cvd..."
copy C:\Downloads\bytecode.cvd "C:\Documents and Settings\All Users\.clamwin\db\bytecode.cvd"
pause
echo "Delete downloading files..."
del C:\Downloads\main.cvd
del C:\Downloads\daily.cvd
del C:\Downloads\bytecode.cvd
pause
Естественно, директорию загрузки C:\Downloads\ замените на свою.
Недельку погонял его на рабочем компе (да, я мудак, лень было тестовый стенд собирать), потом прогнал на компе бесплатный одноразовый DrWeb и Avz4.
Ложные срабатывания. По иронии Clamwin сработал ложно на экзешник как раз Avz4, хотя, может это ненависть к касперскому? Оправданная.
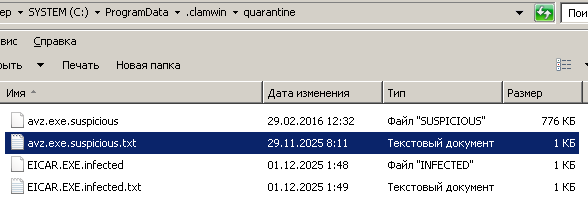
На EICAR Test File сработал штатно, переместил в карантин.
Минус — у монитора всплывашки об угрозе показываются буквально на мгновение.
Плюсы:
+ Опенсурс
+ Работает моментально, не грузит систему
+ Действительно работает.
Минусы:
— Монитор надо ставить отдельно, в комплекте нет.
— За официальным сайтом все-таки следить надо, и не оставлять там битые ссылки.
— Обновления только вручную, клаудфлара ебаная сраная ссаная.
— При ручном запуске сам не берет права администратора.
— Со всплывашками какая-то неведомая жопа. Где не надо долго торчат, а где надо, пропадают мгновенно.


![[info]](http://tolik-punkoff.com/wp-content/plugins/lj-ljr-users/img/userinfo-ljr.gif)






